MinimalistYing.io

对于这个问题相信大家或多或少都能答上几点,但是要详细的描述整个过程就没那么容易了。
作为一名 Web 开发者来说,深入理解在浏览器背后发生的事情对于日常开发或者 Debug 来说都很有意义。
下面我会试着尽可能详细的整理一下从我们输入 URL 到浏览器显示页面的整个流程。
浏览器本地强缓存
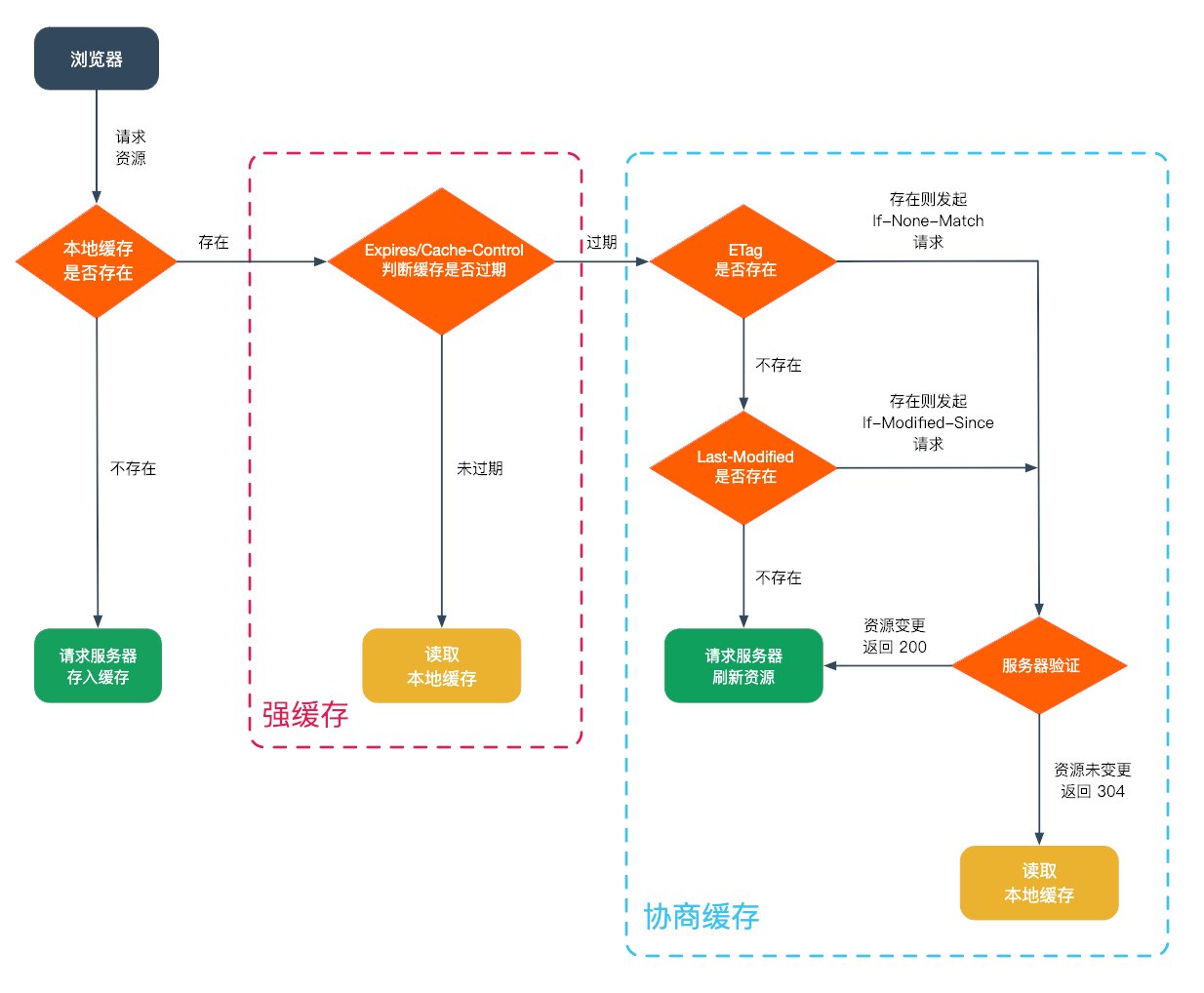
输入域名后首先通过 Cache-Control/Expires 判断是否存在强缓存,如果俩种响应头都存在优先采用 Cache-Control。Cache-Control 可以设置如下几个字段:
- max-age 最长缓存的期限,单位为秒
- no-cache 禁止使用强缓存,必须与服务器进行协商
- no-store 禁用所有缓存
如果存在缓存并且未超过设置的 max-age/Expires 则直接 200 返回对应资源。这里还存在俩种不同的情况,优先从内存中获取对应 Chrome Network 展示的是 200 from memory cache 然后再从本地硬盘中获取对应展示 200 from disk cache。
DNS
如果本地没有符合条件的强缓存,则需要向服务器发起请求获取资源。首先进行的是域名查找工作,目的是根据域名找到对应的服务器 IP 地址。
这一步能做的优化是尽可能的把样式、脚本、图片等文件放到相同域名的服务器下。

图片来自 surmon.me
域名缓存的查找顺序:浏览器缓存->系统缓存(hosts 文件)->路由器缓存->IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存
建立 TCP 连接
拿到 IP 地址后首先需要在浏览器与服务器之间建立起 TCP 连接。也就是通常说的“三次握手”TCP three-way handshake:
- 首先客户端发送
SYN给服务端,此时双方都还无法得到任何信息。 - 服务端收到客户端发来的
SYN后,发送SYN + ACK给客户端,此时服务端能得知客户端可以正常发送信息。 - 客户端收到服务端发来的
SYN + ACK后,发送ACK给服务端,此时客户端能得知服务端可以正常收发信息,在服务端收到该消息后也能得知客户端能正常收到信息。
这个过程主要是为了确保客户端、服务端双方都能正常收发消息。
HTTPS
如果是 HTTPS 请求,还需要多增加一个加密过程。 SSL/TLS 过程
对称加密和非对称加密
(1) 浏览器发送一个连接请求给服务器;服务器将自己的证书(包含服务器公钥S_PuKey)、对称加密算法种类及其他相关信息返回客户端;
(2) 客户端浏览器检查服务器传送到CA证书是否由自己信赖的CA中心签发。若是,执行4步;否则,给客户一个警告信息:询问是否继续访问。
(3) 客户端浏览器比较证书里的信息,如证书有效期、服务器域名和公钥S_PK,与服务器传回的信息是否一致,如果一致,则浏览器完成对服务器的身份认证。
(4) 服务器要求客户端发送客户端证书(包含客户端公钥C_PuKey)、支持的对称加密方案及其他相关信息。收到后,服务器进行相同的身份认证,若没有通过验证,则拒绝连接;
(5) 服务器根据客户端浏览器发送到密码种类,选择一种加密程度最高的方案,用客户端公钥C_PuKey加密后通知到浏览器;
(6) 客户端通过私钥C_PrKey解密后,得知服务器选择的加密方案,并选择一个通话密钥key,接着用服务器公钥S_PuKey加密后发送给服务器;
(7) 服务器接收到的浏览器传送到消息,用私钥S_PrKey解密,获得通话密钥key。
(8) 接下来的数据传输都使用该对称密钥key进行加密。
协商缓存
连接建立后就可以发送 HTTP/HTTPS 请求了,浏览器首先向服务器发送一个 GET 请求获取 HTML。
此时还需先判断一下是否能采用协商缓存,先验证 Etag/If-None-Match,再验证 Last-Modifed/If-Modified-Since。
特别提一下 Etag 是由服务端生成的,其实没有一个绝对的定义,只不过通常是取静态资源的一个 Hash 值,当然你也可以在服务端实现时采用一个类似于版本号的特殊字符串。
另外 Etag 还区分为 Strong Validation 和 Weak Validation,其中弱校验会以 W/ 开头,类似 W/"151e7-z9W90pgoaVCLvfVNoqSuizhxrGE"。至于具体采用哪种,还是得看服务端的实现方式,详情可参考 Where does the W/ in an etag appear from? 以及 Etag: weak vs strong example
任意一个规则匹配则请求返回 304,浏览器直接使用本地缓存的资源。反之请求返回 200,同时带上最新的资源并对本地缓存进行更新。
断开连接
一个 HTTP/HTTPS 请求完成后,浏览器可能会选择断开 TCP 连接(当然也可能会保留连接以供后续使用)。此时需要进行“四次挥手”:
- 客户端向服务端发送
FIN + SEQ通知我这边消息已经发送完了正打算关闭连接。 - 服务端收到后先发送
ACK告知已收到关闭请求,但肯能我这边还有些信息未发送完成。 - 服务端向客户端发送
FIN + SEQ告知消息都已经发送完成,做好了关闭连接的准备。 - 客户端收到
FIN消息后发送ACK告知服务端双方都可以关闭连接了。
需要“四次挥手”主要是由于 TCP 的半关闭(half-close)特性,在一端在结束它的发送后还能继续接收来自另一端数据。
解析 HTML 构建 DOM 树
当浏览器拿到 HTML 后则开始对其进行解析生成 DOM 树。在此期间如果碰到非 async/defer 的 <script> 会暂停解析并优先下载并执行脚本。
这也是为什么在早期总是建议将 <script> 标签放在文档最后面的原因。
构建 CSSOM 树
接下来浏览器会根据已生成的 DOM 树和 CSS 文件来组合生成 CSSOM 树。需要注意 CSS 的加载也会阻塞页面的渲染以及 Javascript 的执行,因为浏览器需求完整的 DOM Tree 以及 CSSOM Tree 才能继续后续的渲染流程。
Render
组合 DOM 树和 CSSOM 树来生成最终的渲染树。
渲染树不会包含不可见的节点,例如 display:none 的节点以及 <head> 标签下的所有节点。
具体渲染细节待后续研究...
参考文档
总结
- 在浏览器地址栏输入 URL
- 判断是否有强缓存
- 域名解析获得 IP 地址
- 三次握手建立 TCP 连接
- 发送 GET 请求并判断是否有协商缓存
- 请求成功返回,如有需要在本地缓存该资源,可能会四次挥手断开连接
- 解析 HTML 生成 DOM 树,构建完成并等待同步的(非
async/defer)脚本执行完成后触发DOMContentLoaded事件。然后等所有资源都加载完毕后才会触发load事件。 - 生成 CSSOM 树
- 根据 DOM 树和 CSSOM 树构建渲染树:
- 渲染最终页面